Prologue and the problem
The compilers course that I’m taking this term (CS444/644) requires us to implement a compiler from scratch. We chose to use Flex/Bison and C++ given the assignment constraints. Quite boring actually. Using Bison, we generate the parse tree and then the AST.
However, our tests were SLOW. We have a “program generator” set up to stress-test the parser rules. This takes around 32s consistently to complete on my laptop and prevents us from scaling up these tests. Of course, before optimizing, we must profile!
Running Valgrind with --tool=callgrind and visualizing the results, we see that the delete and malloc take up quite a bit of the runtime.
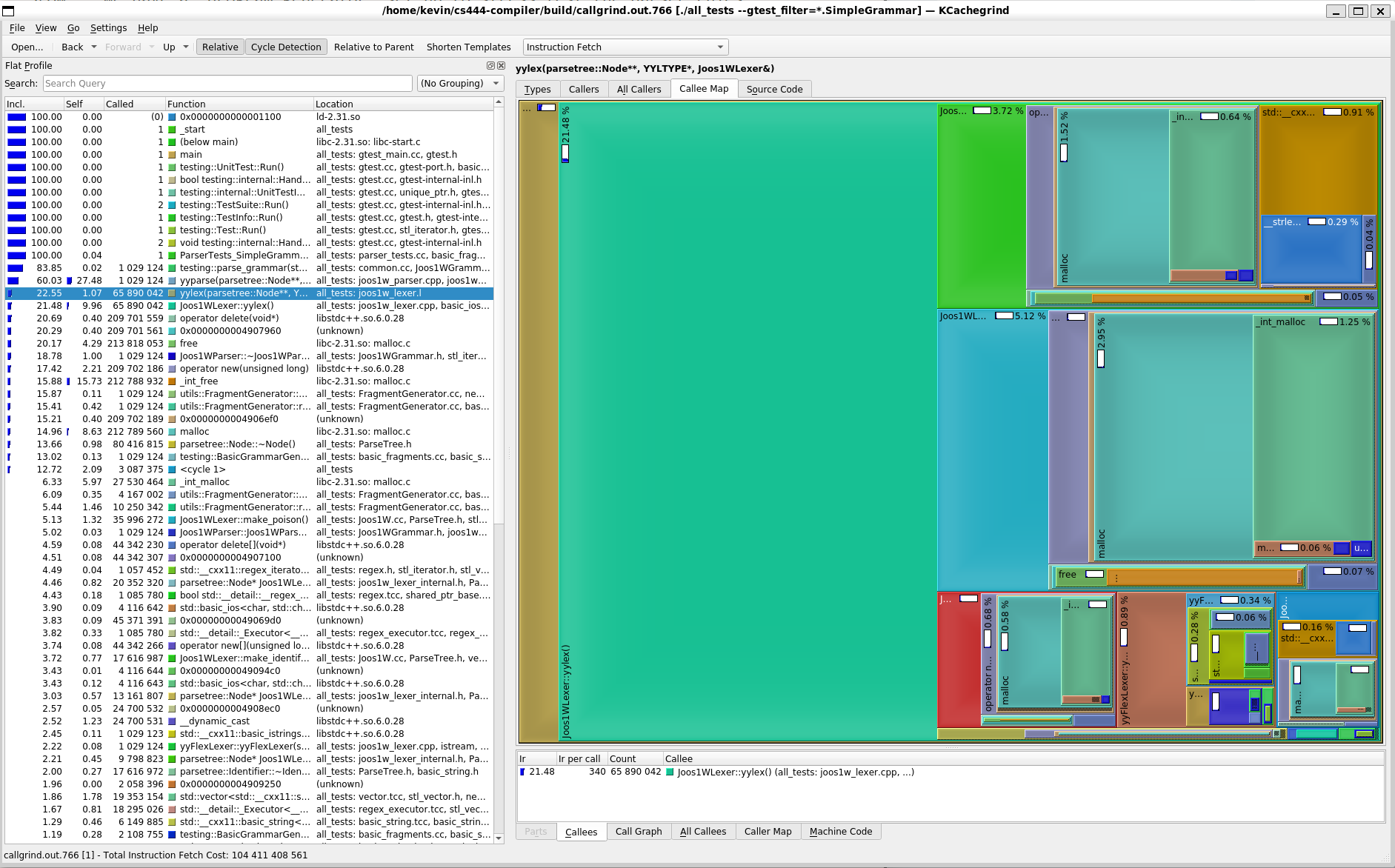
This is when I remembered that Clang uses a bump allocator for their AST (and other structures). This makes sense as we’re making many tiny allocations to build up the trees, and then disposing of the trees at once.
Our custom bump allocator
After reading this blog post, I’ve decided the correct approach was to generalize all our data structures to take in a custom allocator – and ultimately all the STL data structures too. The problem was that the std::pmr::monotonic_buffer_resource which backed the polymorphic_allocator could not reset their buffers “for free.” The only option was to destroy the buffer when in reality it would be more efficient to reuse them (especially for my testing use case).
To do that, we simply inherit from std::pmr::memory_resource and pass that to the allocator instead of the monotonic_buffer_resource object. To do that, we only needed to implement:
1 | |
The initial version of this ignored the alignment field and assumed an 8-byte alignment (a reasonable assumption for a 64-bit architecture). Plus, x86-64 shouldn’t throw alignment exceptions, unlike arm64 does. I just wanted a quick and dirty benchmark.
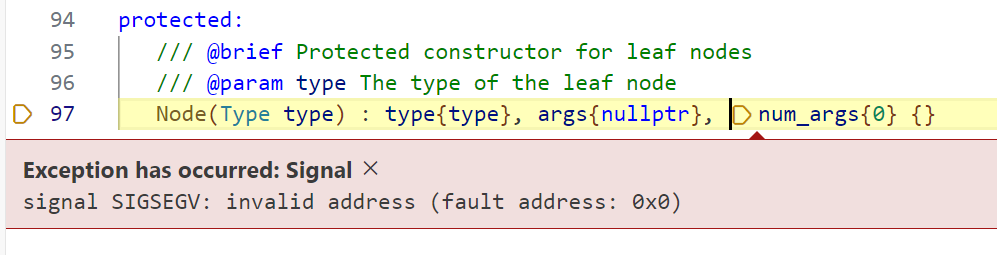
Of course, it doesn’t work the first time. I mean, why would it? However, this is where I was led astray. Looking at the clues:
- Segfault claims to have faulted at 0x0. This usually implies a null pointer dereference.
- The
thispointer is neither null nor an invalid address. - The allocation succeeds twice for
Nodebefore failing on the third allocation, yet the initial buffer for our bump allocator is 4 KiB.
Things don’t add up. Where is the 0x0 coming from? With no other choice, I opened the disassembly view and…
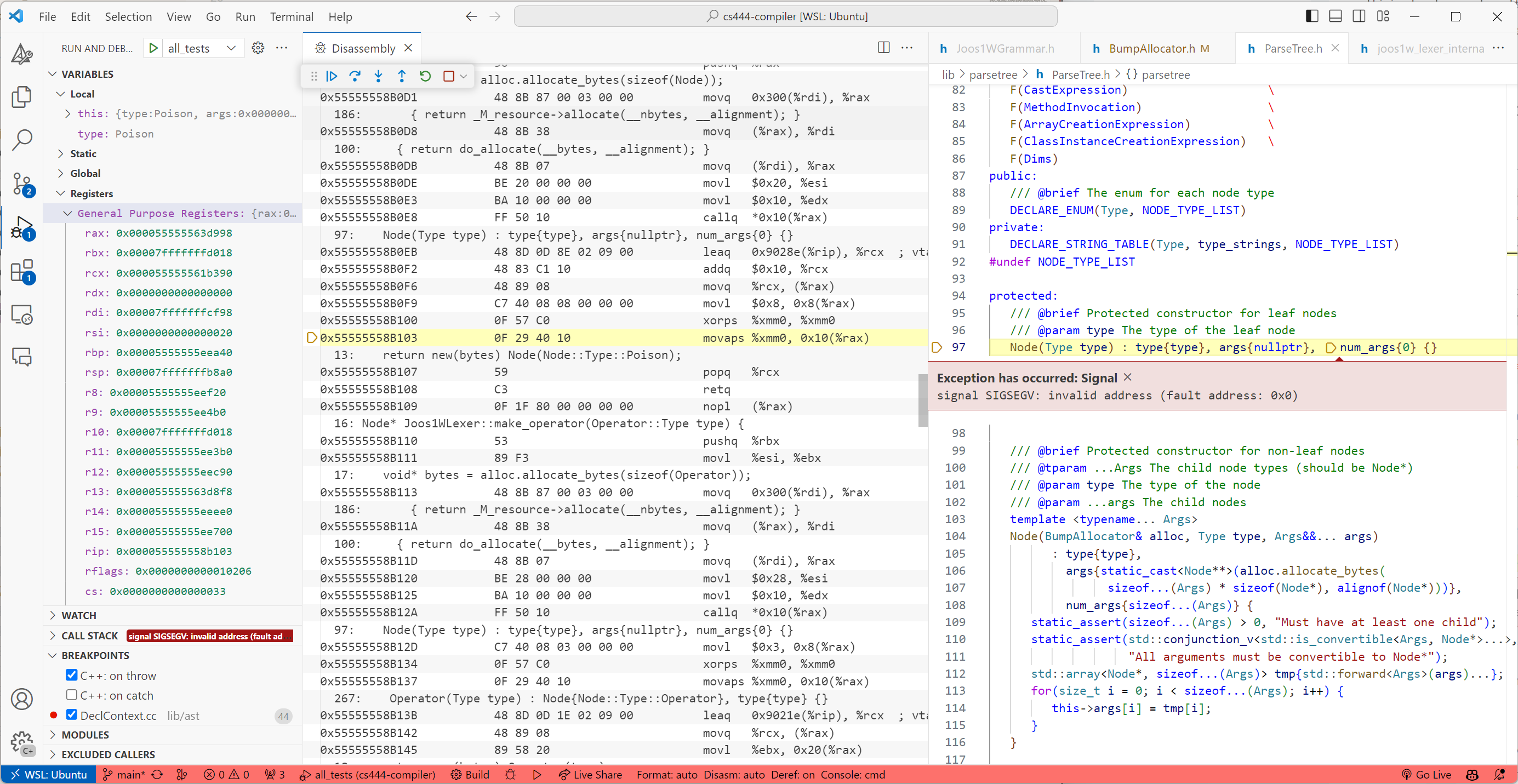
And… I couldn’t see anything wrong immediately. The offending line was (in LLVM syntax):
1 | |
We’re basically moving the value of %xmm0 into the address %rax + 0x10. Yet %rax contains a valid address. But. Something about %xmm0 did not sit right with me because I had a suspicion that it should have special alignment requirements. And it turns out movaps means “Move Aligned Packed Single Precision Floating-Point Values” and required 128-bit alignment.
And, the problem was rectified by aligning allocations to their respective alignment field. Yes, a stupid mistake. But quite a strange set of behaviors to dissect. Was all of this worth it? Yes! I managed to improve the testing times from 32s to 16s consistently.
This is why random assembly knowledge is good to have when you’re rummaging through the depths of systems programming.